Installing Hadoop on Ubuntu 20.04
Below I wrap up how to installing process. This is good for experimental NOT production at all.

What you need to do
- Install Java
- Download Hadoop
- Set environment
- Edit Hadoop XML
- start-dfs.sh
- start-yarn.sh
If success you will see
- localhost:8088 → See Hadoop icon screen
- localhost:9870 → See cluster status screen
Install Java
Update and search for the new JDK.
If you are not familiar with Java, ignore its term we only need JDK.
sudo apt-cache search openjdk
Latest LTS is 11 so I will install 11
javac -version
Download Hadoop
Visit link below. In the command line you will need wget <link> to download it. Extract it to your home directory.
Choose the newer version. Here is 3.3.1 then choose the tar.gz


Setup Environment
Setting the variable for Hadoop and also path for convenient calling of Hadoop command in .bashrc
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
At this point you must be able to call the following binary from anywhere
- hadoop
- hdfs
Edit Hadoop XML and Start
I think Hadoop page is good already. Link below.
Some quick overview will make reading easier
- Hadoop will
sshto localhost so you will need to setup SSH key - You need pseudo distribution mode
- Copy paste XML from Hadoop guide
- Start DFS
- Start YARN
Common error: JAVE_HOME not found
JAVA_HOME need to be set in
NOT in .bashrc !Common error 2: Cannot start YARN
Error when start-yarn.sh
Resource manager still running despite stop-dfs.sh so you need to stop ALL
Note
Just leave the process like that seem like we do not need to run it withsystemctlorserviceas we usually do.
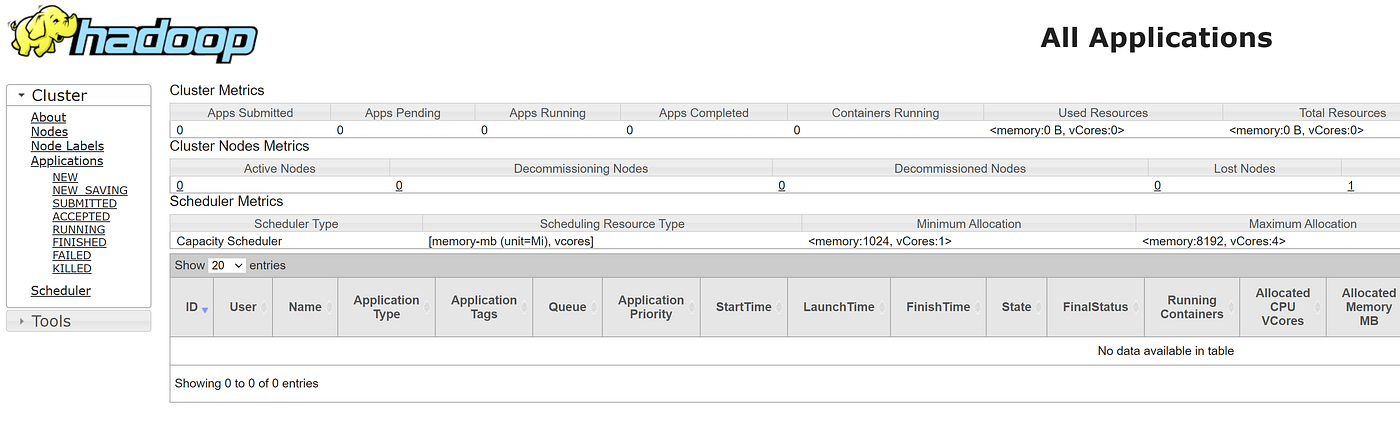
Check the status page
Finally you must see the result like below

Some tips if you deploy it on the server.
Use ssh to forward it down to localhost then open it with your browser.
Hope this helps !

Recommended for you